
AIが牽引するソフトウェア定義のヘテロジニアス・コンピューティング時代

{% module_block module "widget_1688008903796" %}{% module_attribute "child_css" is_json="true" %}{%...
「Linley Fall Processor Conference 2020」の 前回のレポート の続きとして、今回はThe Linley Group主催の「 Spring Processor Conference 2021 」で発表された人工知能(AI)プロセッサやテクノロジーについて紹介します。しかし、今回は前回との大きな違いがあります。 私たち EdgeCortix は今回のLinelyカンファレンスへの参加と同時に、エッジにおいて低レイテンシかつ省電力のAI推論を実現するハードウェアとソフトウェア技術を正式に発表しました。
まず、私たちの講演を取り上げ、次にカンファレンスでの他のAI関連の講演をまとめます。 前回のレポートと同様に、特にAIアクセラレーションを対象としていない講演については、取り上げていないものもあります。
EdgeCortixのテクノロジースタックのプレゼンテーションでは、大きく2つのパートに分けて当社の技術を紹介しました。1つ目は、エッジにおいてディープニューラルネットワーク(DNN)を用いたAI推論を実現するための、モジュール型で、スケーラブル、低レイテンシ かつ 省電力といった特性を備えたIPである Dynamic Neural Accelerator™ (DNA) IPです。そして、2つ目は機械学習エンジニアにシームレスなユーザー体験を提供するMERA (Multi-module Efficient Reconfigurable Accelerator) コンパイラとSDKで、CPUやGPUに対するのと同じように、当社のDNA IPをターゲットにすることができます。MERAは、標準的な機械学習フレームワークの中で直接INT8に量子化されたモデルをサポートすることが可能で、カスタム量子化やモデルの再トレーニングは必要ありません。
EdgeCortixのテクノロジースタックは、既存の多くのAIアクセラレータの弱点となっている低いコンピュート使用率の問題、特にエッジにおける推論に不可欠な小さなバッチサイズおよびバッチ=1の推論に対応できるよう最適化されています。この困難な問題に対するソリューションは2つあります。
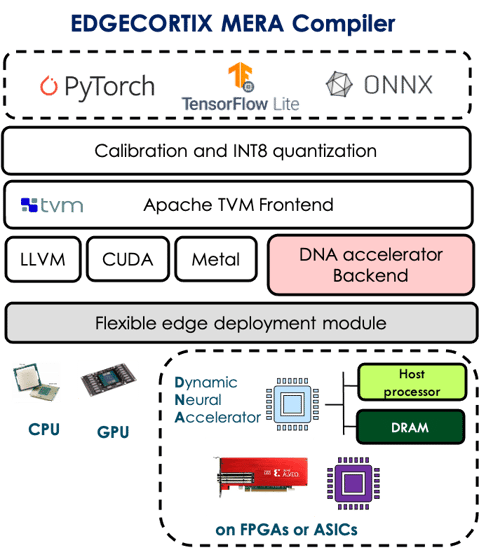 EdgeCortix MERA Compiler & Software Stack (image from official Presentation)
EdgeCortix MERA Compiler & Software Stack (image from official Presentation)
EdgeCortixは、DNA-Aシリーズ IPの製品ラインをLinleyカンファレンスで正式に発表しました。あらかじめ設定された5種類のDNA-Aシリーズ IPは、シングルコア構成で、1.8~54 INT8 TOP/sのピーク演算性能範囲をカバーします。TSMC12 nm製造技術で、動作周波数が 800 MHz であると仮定した場合、最小0.6W未満、 最大8W未満で使用することができます。当然ながら、IPはフルに再構成可能であり、ユーザーはIP内のさまざまなコンピュータ・コンポーネントの数やサイズ、利用可能なオンチップメモリの量を、それぞれののニーズに基づいて調整することができます。
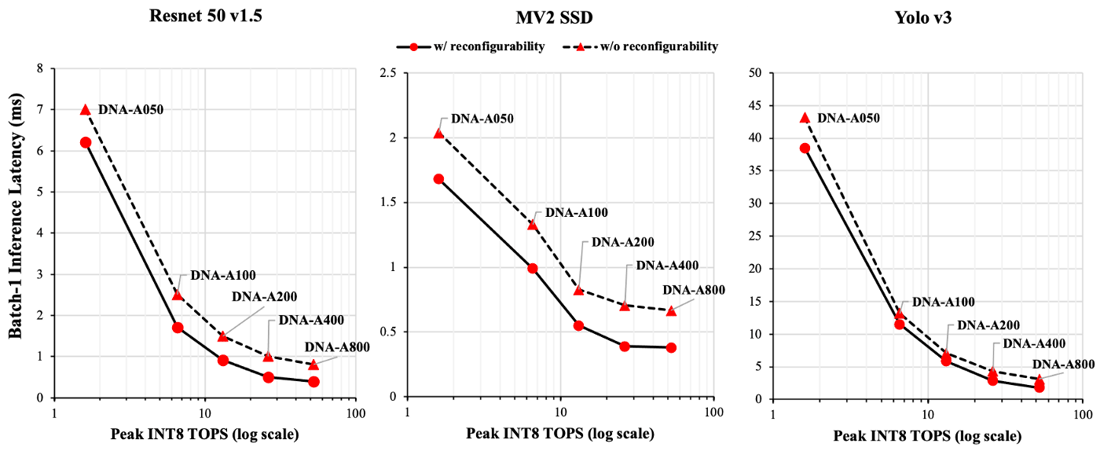
EdgeCortixは現在、LPDDR4メモリモジュールが搭載されたPCI-Eボードに向けて、54-TOP/sのDNA-A800構成を使用した最初のAIチップをテープアウトしています。これは、ボード全体の消費電力が10W未満で、Resnet 50 v1.5 (224x224)、Mobilenet v2 SSD (MV2 SSD 300x300)、 Yolo v3 (416x416) のニューラルネットワークでそれぞれ2500, 2600, 555 IPS (画像/秒)のバッチ=1推論スループットが達成できると期待されています。EdgeCortixのIPと性能に関する詳細は、最新のLinley Group Microprocessor Reportに掲載されています。
それでは、カンファレンスでの他の発表内容を見ていきましょう。
DeepAIは、前回のカンファレンスと同様にFPGA上で高速化された8ビット量子化トレーニングプロセスについて発表しました。あまり新しいことは語られなかったのですが、前回よりもさらにハイレベルなプレゼンテーションでした。今回は、GPUでの固定小数点8ビット学習と標準的なFP32学習による精度についても報告し、Resnet 50を用いた8ビット分類学習では0.3%以下の精度低下、Tiny Yolo v3を用いた8ビット物体検出の再トレーニングではFP32と比較すると、mAPの低下がないことを指摘しました。DeepAIでは主に小売業界をターゲットにしており、果物や食料品などの関連データセットに焦点を当てていることから、自動運転車やモバイルロボットなど、よりクリティカルなビジョンアプリケーションにおいて、彼らの8ビットトレーニングがどのように機能するかは明らかではありません。
Expederaは、ステルスモードから抜け出して、エッジ推論用のニューラルネットワークエンジンを発表しました。ネットワーク領域にパケット交換の原理が応用された独自設計のASICを使用することにより、ニューラルネットワークの分解、依存性分析、スケジューリング、リソース管理など、ソフトウェアので複雑とされる要素をすべてハードウェアに移し、コンパイラの代わりに「トランスレータ」を用いて、与えられたニューラルネットワークを自社のハードウェア上で動作する仕様に変換したと発表しました。
彼らのプレゼンテーションは非常にハイレベルでした。ハードウェアについては、同期や値を戻す必要がない深いパイプライン構造で、決定論的レイテンシを実装しているそうで、有用であると感じましたが、漠然としたことしか述べられていませんでした。同社は、1TOP/sから100TOP/sまで拡張可能で、INT8とINT16/FP16をサポートするモノリシックIPを提供しています。現在は、Tesnorflow/TFLiteにのみ対応しているようです。TSMCの7nmプロセスでテープアウトしたチップでは、Resnet 50の推論で2010IPS/Wを実現したと主張していました。しかし、プレゼンテーションではバッチサイズについての言及はありませんでした。カンファレンスと同時に発表されたLinleyのレポートを読むと、彼らが主張しているIPS/Wは、実際には32TOP/sのフルチップのIPS/Wではなく、チップ内の一部のコンピュートタイルをオフにして、ピーク性能を8TOP/sにまで下げた後のIPS/Wであることが分かりました。また、この数値は実際にはバッチサイズ=1ではなく16であることから、エッジワークロードにはあまり向かず、競合他社と比較すると高い使用率を実現するという同社の主張とは矛盾しているようです。大規模なGPUにおいても、バッチサイズ=16で高い使用率を得ることは可能です
Hailoは、ハードウェアとソフトウェアの最新状況を発表しましたが、ようやく妥当な数字を出すことができたようです。Hailoのチップのピーク性能は26 INT8 TOP/sで、Resnet 50で1223 FPS、3Wを達成したと報告していましたが、バッチサイズについては言及されていませんでした。奇妙なことに、彼らはMLPerfの結果を引用して、他社の結果に対して批判をしていました。MLPerfはまさに、どのハードウェアも同じ条件下で結果を比較できる公平なベンチマーク環境を提供することで、このようなことが起こるのを防ぐ仕組みのはずです。同社のチップはMLPerfでは、パフォーマンスを十分に発揮できなかったようです。(v0.5での結果のようですが)また、性能数値については、Yolo v5(640x640)がバッチサイズ=6で191FPS、消費電力4W以下、Mobilenet v1(300x300)がバッチサイズ=16で1036FPS、消費電力2W、シングルストリームのCenterNet-ResNet-18とResNet-18-FCN16が60FPSで消費電力3.2Wという結果になったと報告していました。また、ソフトウェアについては、「Layor fusion」に対応したことを示すスライドもあり、供給可能な異なるタイプのM.2やmPCI-Eのボードについても紹介されていました。
HailoのチップにはDRAMインターフェイスがなく、オンチップメモリに収まらないものはPCI-E経由で直接チップにストリーミングする必要があり、同社のボードはすべてPCI-E 4xインターフェイスしか備えていないという事実を考慮すると、主要なパフォーマンスのボトルネックになる可能性が非常に高くなるということも覚えておくとよいでしょう。
Innateraは、同社のエッジで超省電力を実現するパターン認識用のニューロモルフィックチップを紹介しました。そのチップはアナログで、スパイキングニューラルネットワーク向けに設計されています。彼らの設計のユニークな点の1つは、隣接するニューロン間のショートレンジの接続密度がより高く、異なるニューロンクラスタ間のグローバル接続の密度がより低い、階層型のインターコネクトを採用していることです。主に音声処理をターゲットにしているようで、教師なし学習や半教師あり学習をサポートし、特にスパイクニューラルネットワークを対象とした新たな学習方法を提案しているとのことでした。同社のSDKとシリコンは今年後半に出荷される予定です。
ARMは、より大きなアドレス空間、ハードリアルタイム決定性、AArch64 ISAをサポートする新しいCortex-R82リアルタイムCPUについて説明しました。興味深いことに、同じプロセッサの異なるコアでリアルタイムタスクとともにフルフラグのLinuxを実行できるため、OSを実行用としてSoC上に追加のCortex-Aを搭載する必要がなくなります。
Intel Habanaは、非GPUインスタンスの最初のセットとして、AWSでのトレーニングチップの提供を開始したことを発表しました。Resnet 50のトレーニング性能では、Gaudiアクセラレータ1台で1,600IPS、8台のGaudiシステムで12,008IPSを達成したとのことです。その結果の脚注には「アクセラレータごとのスループットが最高であると主張しているのではありません」と記載があり、これは「NvidiaのGPUの方がまだ良いパフォーマンスを得られる」という意味であると解釈できるでしょう。また、同社はPyTorchとTensorflowの両方をサポートする「ブリッジ」を備えたソフトウェアについても触れました。5月のMLPerfトレーニングラウンドへの参加や、チップの製造ノードを7nmに下げることも検討しているとのことです。
Tenstorrentsは、16ポートの100Gbit イーサネットの接続を利用して、複数のノードやラックにまたがる非常に大きなメッシュを作成し、1万個単位のチップを効率的に利用できるトレーニング用スーパーコンピュータを作成するために、チップをスケールアップすることについて発表しました。同社は、このような多数のチップに学習性能を拡張できるようテンソルタイリングとパイプラインを活用しようとしているようで、大規模なチップのメッシュを横断するラウティングは、1つのチップ内の同一のコンポーネントを横断するラウティングがすでに機能しているのと同じように機能すると主張しています。興味深いことに、彼らは、大規模 なメッシュチップにおけるテンソルタイルの配置・配線を同社のFPGAやCGRAと比較したところ、前者はより粗い粒度の配線可能なコンポーネントとパケットベースの配線により、配置・配線時間がわずか数分単位で済んだという結果を報告しました。
Graphcoreは、TensorFlow、PyTorch、Popartのほか、さまざまなコンテナ、仮想化、モニタリング技術をサポートした、自社製チップの大規模なクラスタ上でAI学習をスケールアウトするためのソフトウェアに主に焦点を絞って発表していました。MLPerfのトレーニングの次のラウンドに参加し、その後、推論とトレーニングのラウンドにも何度か参加する予定だそうです。彼らは、ある一つのチームのみがMLPerfに取り組んでいると改めて主張していましたが、前回のLinleyカンファレンスでも同様の発言をしていたので、今後の様子を見てみましょう。
Cerebrasはまず、複数のHPCアプリケーションを含め、現在同社のチップで高速化されているさまざまなアプリケーションについて説明し、典型的なHPCシミュレーションにおけるステンシル計算が同社のアーキテクチャにいかにうまくマッピングされているかについて述べました。そして、ウエハースケールチップの第2世代品「WSE-2」を正式に発表しました。このチップは、第一世代のチップと同じシリコンスペースで、チップ上(40GBのオンチップメモリを含む)のあらゆるものを2倍以上に増やしています。また、前世代で16nmプロセス技術が適用されていたのに対して、WSE2では7nmプロセスに移行されています。この新しいチップでは、活性化および重みのスパース性を利用することもネイティブにサポートしており、ソフトウェアを変更することなく、BERTの線形性能スケーリングを達成することができたと述べていました。 講演の中で紹介された興味深い点は、「プルーニングされた大型モデルは、プルーニングされた大型モデルと同じ数のパラメータを持つ小型モデルと比較して、精度の面で優れている」と述べていた点です。
Movellusは、消費電力の削減、ディープFIFOへの依存度の低減によるレイテンシの低減、チップレベルの実装とタイミングクロージャの高速化を実現する同社のAIチップ向けのインテリジェントクロックネットワークについて講演しました。
Arteris IPは、前回に引き続き、同社のNoC IPについて講演を行いましたが、今回は、安全性を含む車載用AIの要件に重点を置いて話されていました。
Rambusは、データセンターのAIチップを主なターゲットとするHBM2Eメモリコントローラについて紹介しました。エッジAIチップについては、低コストで成熟度が高いため、LPDDRまたはGDDRを推奨するとのことでした。
Intelは、FPGAとASICの中間的な役割を果たすeASICソリューションについて説明し、FPGAの設計はすでに完了しているが本格的なASICに移行する準備ができていない顧客に対して、より大容量で低コストで省電力の代替品として同社のソリューションを宣伝していました。eASICは、ロジックやメモリの再構成性はそのままで、コンポーネントの接続性を固定化したようです。したがって、配線変更が必要ない限り、FPGAでは発見できなかったような設計上の問題点を修正することも可能です。このソリューションは、AI領域の変化に適応するための限定的な再構成性をある程度持っているため、AIワークロードにとって興味深い選択肢となるように思われましたが、意外なことにIntelは5Gや軍事用途に特化して宣伝していました。
Linleyカンファレンスは今まで、ハードウェアに特化したカンファレンスであったにもかかわらず、今回はソフトウェアに特化したセッションが充実しており、AIアクセラレータやアクセラレータにおけるソフトウェアの重要性がますます高まっていることがうかがえます。
ARMは、プルーニング、クラスタリング、量子化を考慮したトレーニングを含む「協調最適化」に焦点を当てた、ARMプロセッサ上でニューラルネットワークを最適化し実行するためのソフトウェアとツールについて紹介し、これらの技術をさまざまに組み合わせた場合の精度と圧縮モデルサイズについて報告しました。興味深いことに、彼らは、顧客がImagenetやCOCOのような標準的なデータセットを使うことはほとんどなく、代わりに再トレーニングが必要な独自のデータセットを好んで使う可能性があるため、量子化を考慮したトレーニングは顧客にとって阻害要因とならないだろうと主張していました。ただし、圧縮技術の性能効果については概説していませんでした。
Flex Logixは、TFLiteを直接サポートし、他のフレームワークはONNXを通してのみサポートするソフトウェアスタックについて紹介しました。.onnxや.tfliteを受け取り、実行バイナリを生成するシングルファイルイン・シングルファイルアウトのソフトウェアソリューションを提供します。彼らのソフトウェアは、データをできるだけオンチップに保つ、演算子融合(同社ではダイレクト融合と呼んでいた)やレイヤー融合(同社ではディープ融合と呼んでいた)やWinogradといった典型的な最適化を実装しています。すでにソフトウェアで1つのグラフを複数のボードに分割できるとしているようですが、ボードをまたいでPCI-Eで通信する際のレイテンシのオーバーヘッドが大きいことを考えると、どのようなメリットがあるかは明らかではありません。
プレゼンテーションで明らかにされたもう一つの重要なポイントは、チップの固定部分はMAC演算しか行えず、その他の演算(アクティベーション、プーリングなど)はeFPGAに実装されるということです。どうやら利用可能な演算子のリストがあるようで、既に(最適化された?)RTLがあるということを意味すると思われますが、それでもユーザーは新しいモデルをチップに展開するたびに、配置と配線を行う必要があります。特に、MACベースではない複数の演算をeFPGA内に実装する必要がある場合、FPGA設計をどのように最適化するのか、誰かが新しいカスタム演算器を使いたい場合に、誰がeFPGA用のRTLを提供するのかが明確にされていませんでした。 一般的に見ると、彼らのアプローチは興味深いものの、限られたeFPGAの面積に依存し、RTL設計と配置配線が必要なため、あまりスケーラブルではないようです。同社のソフトウェアとチップは、今年の第3四半期に発売される予定です。
Mythicは、アナログマトリックスプロセッサ用のソフトウェアスタックについても説明しました。 彼らのスタックはMLIRとONNXを受け入れ、ARM/x86などの軽いホストコードとともに、同社のプロセッサ用のバイナリコードを生成します。デバイスバイナリは、フラッシュにあらかじめ書き込まれるウェイトのバンドルと、各計算ブロック内で実行されるRISC-Vコードとデータで構成されています。ウェイトをあらかじめプログラムしておく必要があるため、ウェイトの合計サイズがチップのフラッシュサイズより小さい場合にのみ、チップ上でネットワークを動作させることが可能です。同社は、今ある量でほとんどの標準的なネットワークに対応できるはずであると主張していました。一方、十分なスペースがあり、すべてのウェイトが使用可能なフラッシュ領域に収まる場合、複数のネットワークを同時に実行することも可能です。しかし、フラッシュには書き込み回数に制限があることを忘れないでください。同社の場合、1万回のみです。そのため、積極的な研究や評価にはあまり向かず、ほとんど再プログラムされることのない最終製品として使用されることになるでしょう。
同社は、Resnet 50のバッチ=1推論で250FPSという性能を達成し、最終的にソフトウェアが最適化されれば870FPSになると予測しました。また、Yolo v3 416x416zでは20FPS、さらなるソフトウェアの最適化によりYolo v3 608x608では30FPSの性能が期待できると報告しています。この最適化されたソフトウェアの提供開始時期については発表されませんでした。
BrainChipは、TensorFlowをベースとしたMetaTFソフトウェアスタックについて紹介しました。同社の場合、モデルの学習はTensorFlow Kerasで行われ、その後、CNN2SNN変換ツールに渡されます。また、独自のカスタム量子化ツールも提供しています。MobileNet v1やPointNet++などのDL SNNや、時系列データを用いたネイティブSNNの例を挙げていました。CNNからSNNへの変換がどのように行われるのかについては、現時点では、明確に説明されませんでした。また、オペレータのサポートはあまり広くなく、ほとんどがMACベースの演算に限定されているようです。
Cadenceは、第7世代のTensilica Vision Q8 DSPとVision P1 DSPを発表しました。前者は、精度不明(おそらくINT8)で最大3.8 TOP/s、FP32で192 GFLOP/sの性能を発揮する1024ビットSIMDプロセッサで、ハイエンドモバイルや自動車市場をターゲットとしています。 後者は、最大256GOP/sの性能を提供する128ビットSIMDプロセッサで、常時接続のアプリケーションやスマートセンサーをターゲットとしています。
Tensilica Vision Q8は、INT8からFP64までをサポートし、1サイクルあたり1Kの8ビットMACまたは256個の16ビットMACを提供します。ISAは、深さ16の倍数の畳み込み演算に最適化されています。この DSP の複数のインスタンスをインスタンス化し、Cadence独自のインターコネクトで接続することで、より高いパフォーマンスを発揮することができます。一方、Vision P1 DSPは、INT8からFP32までをサポートし、1サイクルあたり128個の8ビットMACまたは64個の16ビットMACを提供します。Cadenceは、新型DSPと旧型DSPを比較し、正規化された性能の向上を説明しましたが、完全なエンドツーエンドのニューラルネットワーク推論における実際の性能数値については報告されませんでした。
また、IPについてはASIL-BやASIL-Dの認証、ツールについてはISO 26262の認証を維持したまま、TIE(Tensilica Instruction Extension)によるカスタム命令の追加が可能であるISO 26262についても簡単に説明しました。同社のソフトウェアスタックは、OpenCL、Halide DSL、Embedded C/C++、OpenVx Graphsを使用してすべてのDSPのプログラミングを容易にします。そして、一般的な機械学習フレームワークは、ONNXへの変換でサポートされています。
SiFiveは、まずRISC-V Vector Extensionsの概要を説明し、ARM Neonのソースコードを直接RISC-V Vectorアセンブリにコンパイルするツールを提供することで、ARMの市場シェアを切り崩そうとしていることを示唆しました。そして、進化し続けるAIワークロードのオペレータ要件に対応するため、RISC-V Vector ExtensionsとSiFive Intelligence Extensionsを組み合わせた「SiFive Intelligence X280」プロセッサを発表しました。BF16/FP16〜FP64、INT8〜INT64のデータ型と、最大512ビット/サイクルの可変長ベクトル演算をサポートし、マルチコアコヒーレンシーとLinux実行機能を備えた64ビットRISC-V ISAで構築されています。本プロセッサがサポートするSiFive Intelligence Extensionsは、ベクトル拡張のみをサポートする64ビットRISC-Vソリューションと比較して、機械学習のワークロードを高速化することが可能です。このプロセッサはTensorFlowやTensorFlow Liteを使ってターゲットにすることができますが、同社のソリューションを既存のものと比較できるようなAIワークロードの実際の性能数値は提示されませんでした。
Flex Logixは、InferX X1プロセッサとLPDDR4メモリモジュールを1枚ずつ搭載したX1P1およびX1Mボードを発表しました。X1P1 ボードは、4xPCI-E 3/4と16WのTDPを備えた、ハーフハイト、ハーフ幅の PCI-E ボードです。一方、X1MボードはM.2フォームファクタで、TDPは8.2Wです。このボードは、特定の熱や電力要件を満たすためにさらに調整することができますが、報告によると、入力解像度416x416、608x608のYolo v3でそれぞれ30FPS、15FPSの推論速度を達成し、消費電力は6Wに抑えられているとのことです。M.2ボードは、ソフトウェアとコンパイラがサーバーノード内の複数のボード上で推論ワークロードを分割するため、高密度の計算サーバーに適しているようです。これは、PCI-Eを介した通信のレイテンシが大きいことと、同社のボードが4x PCI-Eしか搭載していないことを考慮すると、バッチ=1推論性能を複数のアクセラレータボードで効率的に拡張できない可能性があるためと思われます。そのため、同社のマルチボードサーバーは、アクセラレータ間の通信が不要なバッチ型推論を主な対象としていると思われます。
Qualcommは、先日のMLPerf v1.0ベンチマークでNvidiaの競合製品となったことを証明したCloud AI 100アクセラレータを発表しました。このアクセラレータには、3つのフォームファクタが用意されています。
ソフトウェア面では、QualcommはPyTorchとTensorFlowのネイティブサポートを主張しており、その他のフレームワークはONNXとGlowランタイムを通じてサポートされています。
Linley Spring Processor Conference 2021のまとめは以上です。全体として興味深いイベントであり、今年の秋に開催される次のイベントも楽しみにしています。私たちEdgeCortixからのさらなる情報発信にもご期待ください。
免責事項:この記事は、Hamid Reza Zohouriが個人の見解で作成したものです。この記事で述べられている意見は、著者自身のものであり、必ずしもEdgeCortix Inc.の見解を反映するものではありません。

